Black Monday: How unlikely was it, and could it happen again? (Part IV)
This post is the fourth in a series that will look back on the events of Black Monday, on the occasion of its 30th anniversary, and explore how they might be relevant to contemporary investing. Click here to read the first post, here to read the second, and here to read the third.
In this series of articles, we've looked at a number of quantitative methods for answering the question “at the time it occurred, how likely was a market crash on the scale of Black Monday?”
(Of course, it's possible to model volatility in arbitrarily complicated ways - we've just had a look at the lowest-hanging fruit in this overview series.1)
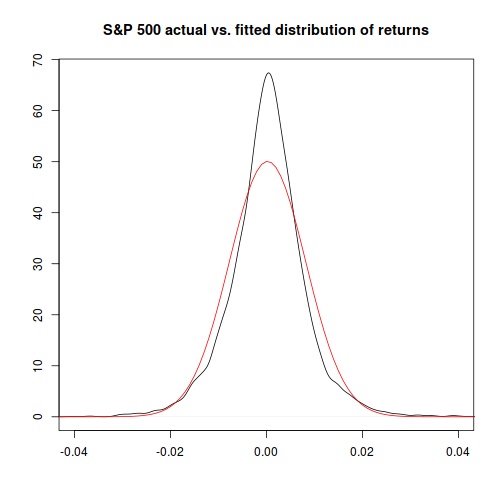
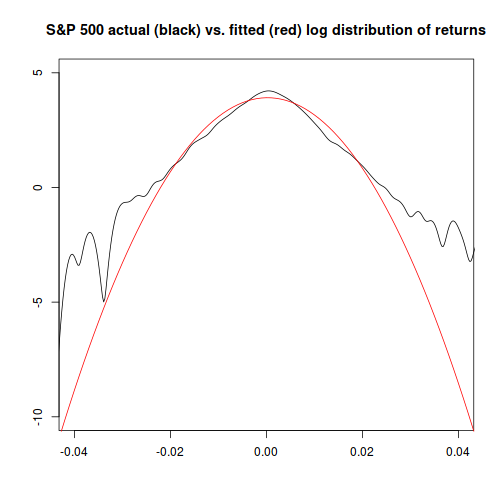
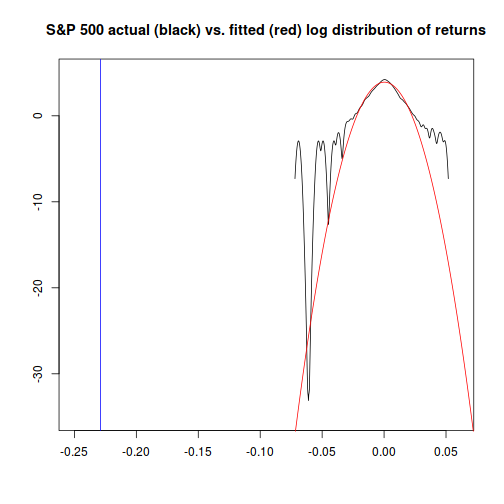
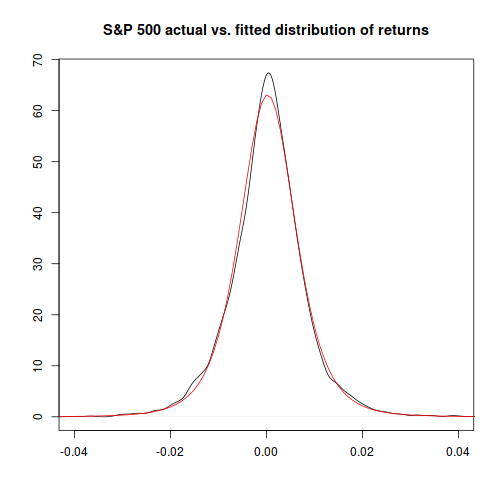
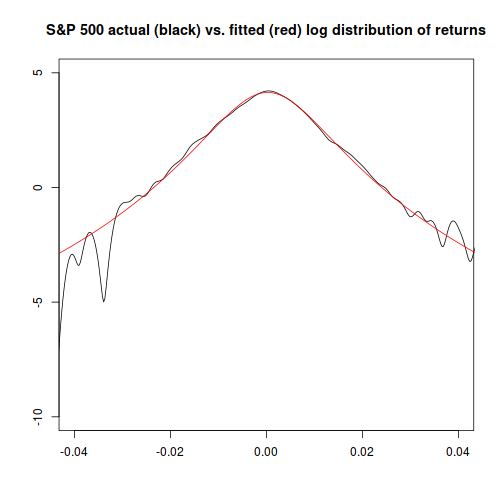
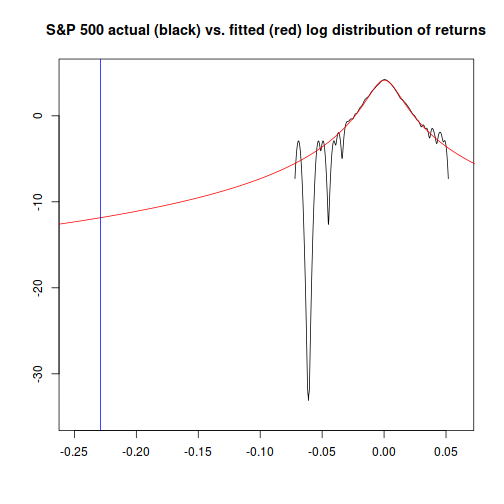
The four answers from the approaches we used range from “basically impossible” for the normal distribution method, to “about once every six to seven thousand years” for the method that combines time-varying volatility with the Student-t distribution.
Since Black Monday did, in fact, happen - but hasn't happened since - I would lean towards asserting that the model which gives the highest probability is probably the one that will be the most accurate going forward.2
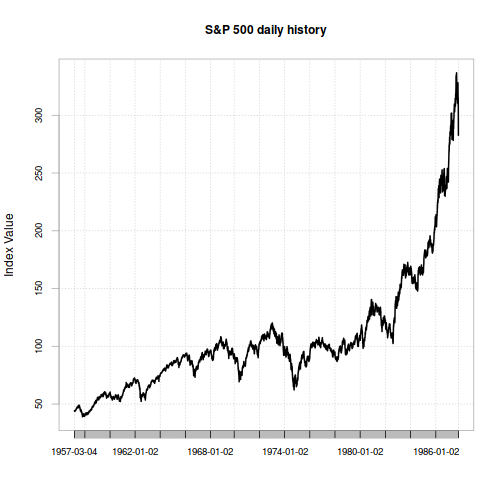
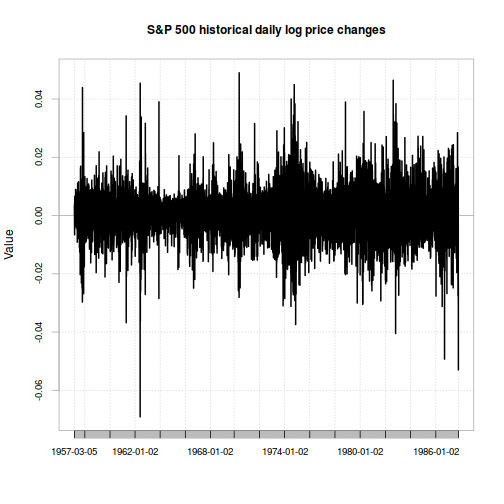
This naturally leads to the question of how likely another event like Black Monday would be today. As we mark the 30th anniversary, volatility has actually been unusually low by historical standards - so much so that there's a fair amount of concern about the market's lack of concern.
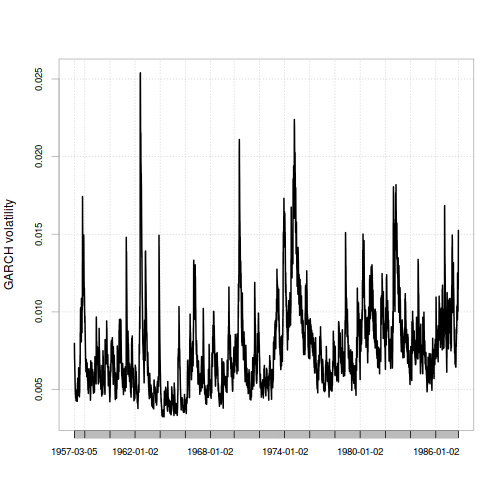
But all four of these methods are easy to use to make a prediction about today: just extend the input data to the present. If you do so, you'll see that both of the static methods indicate a higher probability of a Black Monday event now than they did when just looking at data from before the event. This is because since the event happened, both models show a higher probability of it. (In fact, the static Student-t method indicates such an event should happen roughly once every 300 years.) On the other hand, both of the dynamic (GARCH) methods indicate that the likelihood of another Black Monday event right now is very low - since while Black Monday did happen, it happened a long time ago and recent market volatility has been very subdued, unlike the increasing turmoil in the weeks leading up to Black Monday.
So, what are the takeaways from this exercise?
- The probability estimate you get depends on the model you use.
- Overall historical probability of an event can differ from the probability of that event at a particular point in time.
- While Black Monday was very improbable by any measure, time-varying volatility models did indicate that market risk was growing.
- The normal distribution is probably a bad choice to model extreme events. (Though it may be fine for answering other questions.)
- While an event on the scale of Black Monday may occur every century or two, it's fairly unlikely at the moment since recent volatility has been low.
This concludes the series… I hope you've found it interesting and useful. Feel free to drop us a line if you have questions or comments.
Further reading:
The book “A First-Class Catastrophe: The Road to Black Monday, the Worst Day in Wall Street History” has recently been released. It's an in-depth account of the events of Black Monday, and While I haven't read it yet myself the reviews look good.
The market is constantly providing lessons to be learned. Here's a good one for quants, related to Black Monday.
Bloomberg has a great retrospective with commentary from many leading names in finance that you can check out here.
1: For example, you could fit an assymetric distribution to trailing returns, or use market-implied volatility from options prices instead of trailing returns.
2: I believe that all four approaches shown in this series are simple enough that given the amount of input data, overfitting is not likely to be a serious concern.

 = \frac{\Gamma(\frac{\nu + 1}{2})}{\Gamma(\frac{\nu}{2})\sqrt{\frac{1}{2}\tau\nu\sigma^2}} \left(1+\frac{1}{\nu}\left(\frac{x-\mu}{\sigma}\right)^2\right)^{-\frac{\nu+1}{2}}")
 = \frac{1}{\sqrt{\tau\sigma^2} } \; e^{ -\frac{(x-\mu)^2}{2\sigma^2} }")